bamCompare¶
bamCompare can be used to generate a bigWig or bedGraph file based on two BAM files that are compared to each other while being simultaneously normalized for sequencing depth.
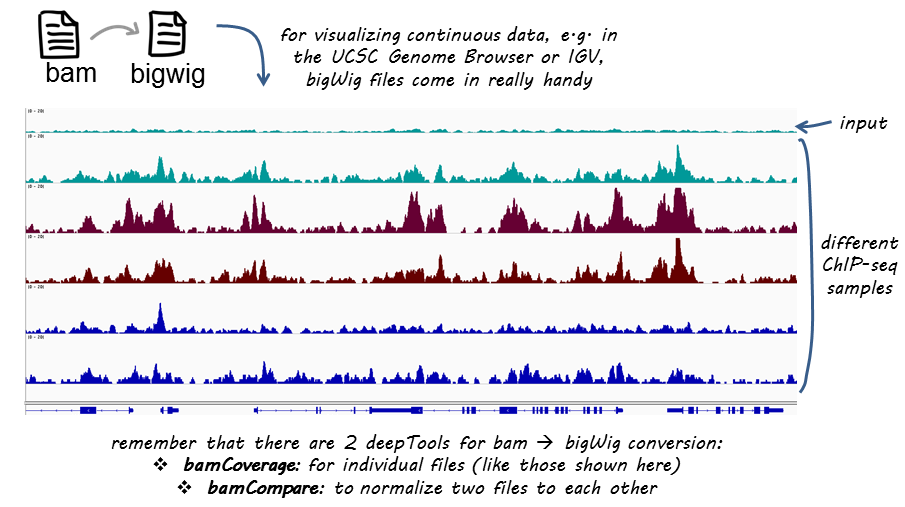
If you are not familiar with BAM, bedGraph and bigWig formats, you can read up on that in our Glossary of NGS terms
This tool compares two BAM files based on the number of mapped reads. To compare the BAM files, the genome is partitioned into bins of equal size, then the number of reads found in each bin is counted per file, and finally a summary value is reported. This value can be the ratio of the number of reads per bin, the log2 of the ratio, or the difference. This tool can normalize the number of reads in each BAM file using the SES method proposed by Diaz et al. (2012) “Normalization, bias correction, and peak calling for ChIP-seq”. Statistical Applications in Genetics and Molecular Biology, 11(3). Normalization based on read counts is also available. The output is either a bedgraph or bigWig file containing the bin location and the resulting comparison value. By default, if reads are paired, the fragment length reported in the BAM file is used. Each mate, however, is treated independently to avoid a bias when a mixture of concordant and discordant pairs is present. This means that each end will be extended to match the fragment length.
usage: bamCompare -b1 treatment.bam -b2 control.bam -o log2ratio.bw
- Required arguments
--bamfile1, -b1 Sorted BAM file 1. Usually the BAM file for the treatment. --bamfile2, -b2 Sorted BAM file 2. Usually the BAM file for the control. - Output
--outFileName, -o Output file name. --outFileFormat=bigwig, -of=bigwig Output file type. Either “bigwig” or “bedgraph”.
Possible choices: bigwig, bedgraph
- Optional arguments
--scaleFactorsMethod=readCount Method to use to scale the samples. Default “readCount”.
Possible choices: readCount, SES
--sampleLength=1000, -l=1000 *Only relevant when SES is chosen for the scaleFactorsMethod.* To compute the SES, specify the length (in bases) of the regions (see –numberOfSamples) that will be randomly sampled to calculate the scaling factors. If you do not have a good sequencing depth for your samples consider increasing the sampling regions’ size to minimize the probability that zero-coverage regions are used. --numberOfSamples=100000.0, -n=100000.0 *Only relevant when SES is chosen for the scaleFactorsMethod.* Number of samplings taken from the genome to compute the scaling factors. --scaleFactors Set this parameter manually to avoid the computation of scaleFactors. The format is scaleFactor1:scaleFactor2.For example, –scaleFactor 0.7:1 will cause the first BAM file tobe multiplied by 0.7, while not scaling the second BAM file (multiplication with 1). --ratio=log2 The default is to output the log2ratio of the two samples. The reciprocal ratio returns the the negative of the inverse of the ratio if the ratio is less than 0. The resulting values are interpreted as negative fold changes. *NOTE*: Only with –ratio subtract can –normalizeTo1x or –normalizeUsingRPKM be used.
Possible choices: log2, ratio, subtract, add, reciprocal_ratio
--pseudocount=1 small number to avoid x/0. Only useful together with –ratio log2 or –ratio ratio . --version show program’s version number and exit --binSize=50, -bs=50 Size of the bins, in bases, for the output of the bigwig/bedgraph file. --region, -r Region of the genome to limit the operation to - this is useful when testing parameters to reduce the computing time. The format is chr:start:end, for example –region chr10 or –region chr10:456700:891000. --numberOfProcessors=max/2, -p=max/2 Number of processors to use. Type “max/2” to use half the maximum number of processors or “max” to use all available processors. --verbose=False, -v=False Set to see processing messages. - Read coverage normalization options
--normalizeTo1x Report read coverage normalized to 1x sequencing depth (also known as Reads Per Genomic Content (RPGC)). Sequencing depth is defined as: (total number of mapped reads * fragment length) / effective genome size. The scaling factor used is the inverse of the sequencing depth computed for the sample to match the 1x coverage. To use this option, the effective genome size has to be indicated after the option. The effective genome size is the portion of the genome that is mappable. Large fractions of the genome are stretches of NNNN that should be discarded. Also, if repetitive regions were not included in the mapping of reads, the effective genome size needs to be adjusted accordingly. Common values are: mm9: 2,150,570,000; hg19:2,451,960,000; dm3:121,400,000 and ce10:93,260,000. See Table 2 of http://www.plosone.org/article/info:doi/10.1371/journal.pone.0030377 or http://www.nature.com/nbt/journal/v27/n1/fig_tab/nbt.1518_T1.html for several effective genome sizes. --normalizeUsingRPKM=False Use Reads Per Kilobase per Million reads to normalize the number of reads per bin. The formula is: RPKM (per bin) = number of reads per bin / ( number of mapped reads (in millions) * bin length (kb) ). Each read is considered independently,if you want to only count either of the mate pairs inpaired-end data, use the –samFlag option. --ignoreForNormalization, -ignore A list of space-delimited chromosome names containing those chromosomes that should be excluded for computing the normalization. This is useful when considering samples with unequal coverage across chromosomes, like male samples. An usage examples is –ignoreForNormalization chrX chrM. --skipNonCoveredRegions=False, --skipNAs=False This parameter determines if non-covered regions (regions without overlapping reads) in a BAM file should be skipped. The default is to treat those regions as having a value of zero. The decision to skip non-covered regions depends on the interpretation of the data. Non-covered regions may represent, for example, repetitive regions that should be skipped. --smoothLength The smooth length defines a window, larger than the binSize, to average the number of reads. For example, if the –binSize is set to 20 and the –smoothLength is set to 60, then, for each bin, the average of the bin and its left and right neighbors is considered. Any value smaller than –binSize will be ignored and no smoothing will be applied. - Read processing options
--extendReads=False, -e=False This parameter allows the extension of reads to fragment size. If set, each read is extended, without exception. *NOTE*: This feature is generally NOT recommended for spliced-read data, such as RNA-seq, as it would extend reads over skipped regions. *Single-end*: Requires a user specified value for the final fragment length. Reads that already exceed this fragment length will not be extended. *Paired-end*: Reads with mates are always extended to match the fragment size defined by the two read mates. Unmated reads, mate reads that map too far apart (>4x fragment length) or even map to different chromosomes are treated like single-end reads. The input of a fragment length value is optional. If no value is specified, it is estimated from the data (mean of the fragment size of all mate reads). --ignoreDuplicates=False If set, reads that have the same orientation and start position will be considered only once. If reads are paired, the mate’s position also has to coincide to ignore a read. --minMappingQuality If set, only reads that have a mapping quality score of at least this are considered. --centerReads=False By adding this option, reads are centered with respect to the fragment length. For paired-end data, the read is centered at the fragment length defined by the two ends of the fragment. For single-end data, the given fragment length is used. This option is useful to get a sharper signal around enriched regions. --samFlagInclude Include reads based on the SAM flag. For example, to get only reads that are the first mate, use a flag of 64. This is useful to count properly paired reads only once, as otherwise the second mate will be also considered for the coverage. --samFlagExclude Exclude reads based on the SAM flag. For example, to get only reads that map to the forward strand, use –samFlagExclude 16, where 16 is the SAM flag for reads that map to the reverse strand.
Warning
The filtering by deepTools is done after the scaling factors are calculated!
Warning
If you know that your files will be strongly affected by the kind of filtering you would like to apply (e.g., removal of duplicates with --ignoreDuplicates or ignoring reads of low quality) then consider removing those reads beforehand.
| deepTools Galaxy. | code @ github. |