bamPEFragmentSize¶
This tool calculates the fragment sizes for read pairs given a BAM file from paired-end sequencing.Several regions are sampled depending on the size of the genome and number of processors to estimate thesummary statistics on the fragment lengths. Properly paired reads are preferred for computation, i.e., it will only use discordant pairs if no concordant alignments overlap with a given region. The default setting simply prints the summary statistics to the screen.
usage: bamPEFragmentSize [-h] [--bamfiles bam files [bam files ...]]
[--histogram FILE] [--numberOfProcessors INT]
[--samplesLabel SAMPLESLABEL [SAMPLESLABEL ...]]
[--plotTitle PLOTTITLE]
[--maxFragmentLength MAXFRAGMENTLENGTH] [--logScale]
[--binSize INT] [--distanceBetweenBins INT]
[--blackListFileName BED file] [--verbose]
[--version]
- optional arguments
--bamfiles, -b List of BAM files to process --histogram, -hist Save a .png file with a histogram of the fragment length distribution. --numberOfProcessors, -p Number of processors to use. The default is to use 1. --samplesLabel Labels for the samples plotted. The default is to use the file name of the sample. The sample labels should be separated by spaces and quoted if a label itselfcontains a space E.g. –samplesLabel label-1 “label 2” --plotTitle, -T Title of the plot, to be printed on top of the generated image. Leave blank for no title. --maxFragmentLength The maximum fragment length in the histogram. A value of 0 (the default) indicates to use twice the mean fragment length --logScale Plot on the log scale --binSize, -bs Length in bases of the window used to sample the genome. (default 1000) --distanceBetweenBins, -n To reduce the computation time, not every possible genomic bin is sampled. This option allows you to set the distance between bins actually sampled from. Larger numbers are sufficient for high coverage samples, while smaller values are useful for lower coverage samples. Note that if you specify a value that results in too few (<1000) reads sampled, the value will be decreased. (default 1000000) --blackListFileName, -bl A BED file containing regions that should be excluded from all analyses. Currently this works by rejecting genomic chunks that happen to overlap an entry. Consequently, for BAM files, if a read partially overlaps a blacklisted region or a fragment spans over it, then the read/fragment might still be considered. --verbose Set if processing data messages are wanted. --version show program’s version number and exit
Example usage¶
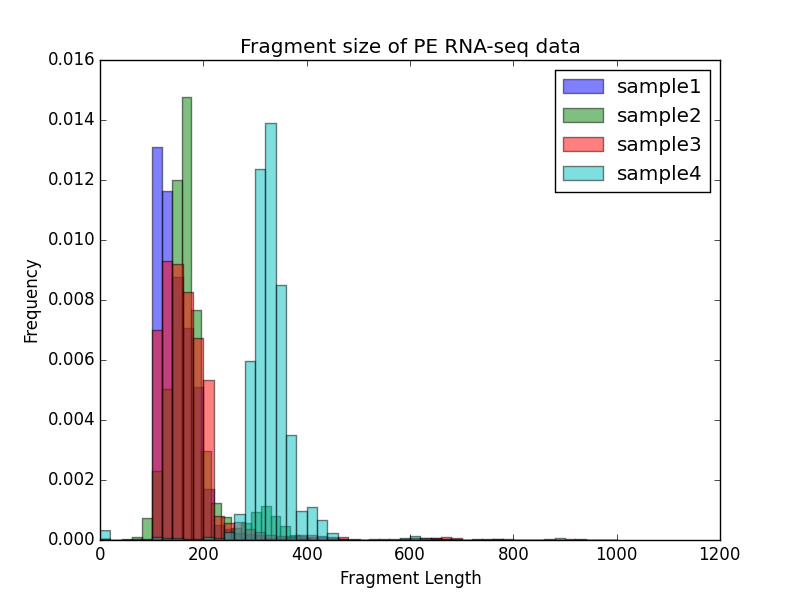
$ deepTools2.0/bin/bamPEFragmentSize \
-hist fragmentSize.png \
-T "Fragment size of PE RNA-seq data" \
--maxFragmentLength 1000 \
-b testFiles/RNAseq_sample1.bam testFiles/RNAseq_sample2.bam \
testFiles/RNAseq_sample3.bam testFiles/RNAseq_sample4.bam \
-samplesLabel sample1 sample2 sample3 sample4
## Output
BAM file : testFiles/RNAseq_sample1.bam
Sample size: 10815
Fragment lengths:
Min.: 0.0
1st Qu.: 311.0
Mean: 8960.68987517
Median: 331.0
3rd Qu.: 362.0
Max.: 53574842.0
Std: 572421.46625
Read lengths:
Min.: 20.0
1st Qu.: 101.0
Mean: 99.1621821544
Median: 101.0
3rd Qu.: 101.0
Max.: 101.0
Std: 9.16567362755
BAM file : testFiles/RNAseq_sample2.bam
Sample size: 6771
Fragment lengths:
Min.: 43.0
1st Qu.: 148.0
Mean: 176.465071629
Median: 164.0
3rd Qu.: 185.0
Max.: 500.0
Std: 53.733877263
......(output truncated)
| deepTools Galaxy. | code @ github. |