Example usage¶
How we use deepTools for ChIP-seq analyses¶
deepTools started off as a package for ChIP-seq analysis, which is why you’ll find many ChIP-seq examples in our documentation. Here are slides that we used for teaching at the University of Freiburg, with more details on the deepTools usage and aims in regard to ChIP-seq. To get a feeling fo what deepTools can do, we’d like to give you a brief glimpse into how we typically use deepTools for ChIP-seq analyses.
Note
While some tools, such as plotFingerprint, specifically address ChIP-seq-issues, the majority of tools is widely applicable to deep-sequencing data, including RNA-seq.
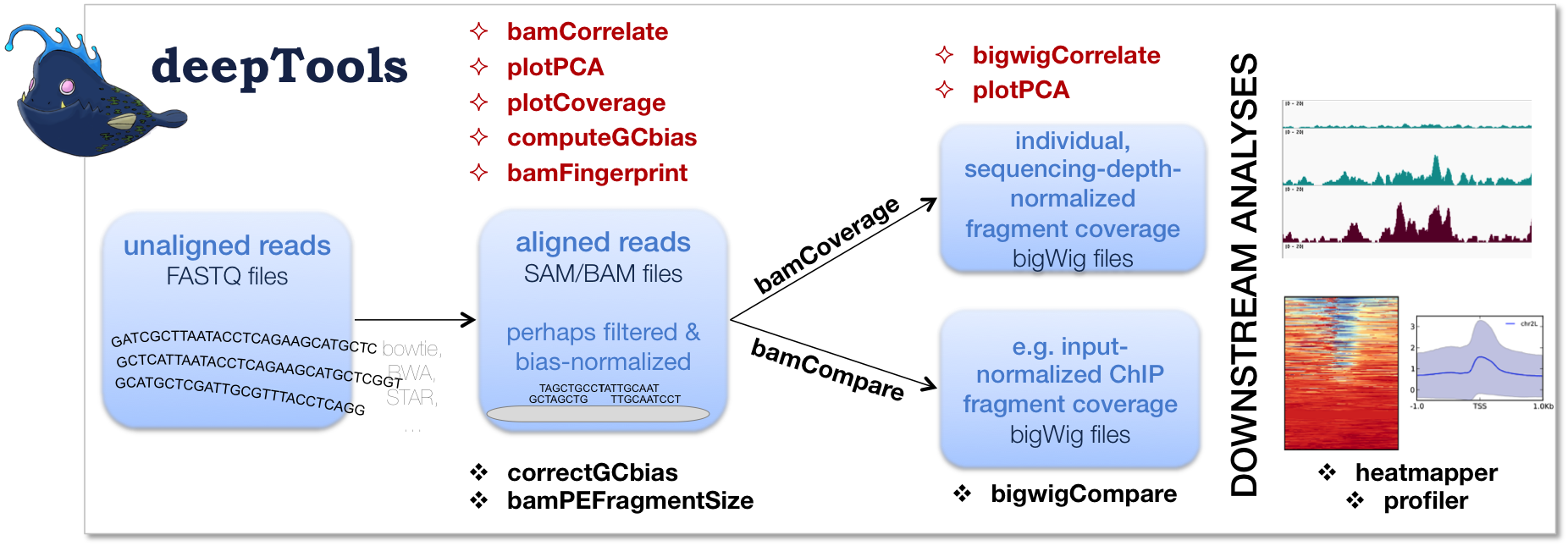
As shown in the flow chart above, our work usually begins with one or more FASTQ file(s) of deeply-sequenced samples. After preliminary quality control using FASTQC, we align the reads to the reference genome, e.g., using bowtie2. The standard output of bowtie2 (and other mapping tools) is in the form of sorted and indexed BAM files that provide the common input and starting point for all subsequent deepTools analyses. We then use deepTools to assess the quality of the aligned reads:
- Correlation between BAM files (
multiBamSummaryandplotCorrelation). Together these two modules perform a very basic test to see whether the sequenced and aligned reads meet your expectations. We use this check to assess reproducibility - either between replicates and/or between different experiments that might have used the same antibody or the same cell type, etc. For instance, replicates should correlate better than differently treated samples. - Correlation between bigWig files (
multiBigwigSummaryandplotCorrelation). Sometimes we want to compare our alignments with genome-wide data stored as “tracks” in public repositories or other more general scores that are not necessarily based on read-coverage. To this end, we provide an efficient module to handle bigWig files and compare them and their correlation for several samples. In addition we provide a tool (plotPCA) to perform a Principle Component Analysis of the same underlying data. - GC-bias check (
computeGCbias). Many sequencing protocols require several rounds of PCR-based DNA amplification, which often introduces notable bias, due to many DNA polymerases preferentially amplifying GC-rich templates. Depending on the sample (preparation), the GC-bias can vary significantly and we routinely check its extent. In case we need to compare files with different GC biases, we use the correctGCbias module to match the GC bias. See the paper by Benjamini and Speed for many insights into this problem. - Assessing the ChIP strength. We do this quality control step to get a feeling for the signal-to-noise ratio in samples from ChIP-seq experiments. It is based on the insights published by Diaz et al..
Once we’re satisfied with the basic quality checks, we normally convert the large BAM files into a leaner data format, typically bigWig. bigWig files have several advantages over BAM files, mainly stemming from their significantly decreased size:
- useful for data sharing and storage
- intuitive visualization in Genome Browsers (e.g. IGV)
- more efficient downstream analyses are possible
The deepTools modules bamCompare and bamCoverage not only allow for
simple conversion of BAM to bigWig (or
bedGraph for that matter), but also for normalization, such that
different samples can be compared despite differences in their
sequencing depth, GC biases and so on.
Finally, once all the files have passed our visual inspections, the fun
of downstream analysis with computeMatrix, heatmapper and profiler can begin!