Step-by-step protocols
This section should give you an overview of how to do many common tasks. We’re using screenshots from Galaxy here.
If you’re using the command-line version you can easily follow the given examples since the vast majority of parameters is either indicated in Galaxy, too. Otherwise, just type the program name and the help option (e.g. /deepTools/bin/bamCoverage --help), which will show you all the parameters and options available. Alternatively, you can follow the respective link to the tool documentation here on readthedocs.
Note
For support or questions please post to Biostars. For bug reports and feature requests please open an issue <on github.
All protocols assume that you have uploaded your files into a Galaxy instance with a deepTools installation, e.g., deepTools Galaxy. If you need help to get started with Galaxy in general, e.g. to upload your data, see Using deepTools within Galaxy and Data import into Galaxy.
Tip
If you would like to try out the protocols with sample data, go to deepTools Galaxy –> “Shared Data” –> “Data Libraries” –> “deepTools Test Files”. Simply select BED/BAM/bigWig files and click, “to History”. You can also download the test data sets to your computer by clicking “Download” at the top.
QC and data processing
I have downloaded/received a BAM file - how do I generate a file I can look at in a genome browser?
tool: bamCoverage
input: your BAM file with aligned reads
Of course, you could also look at your BAM file in the genome browser. However, generating a bigWig file of read coverages will drastically reduce the size of the file, it also allows you to normalize the coverage to 1x sequencing depth, which makes a visual comparison of multiple files more feasible.

How can I assess the reproducibility of my sequencing replicates?
Typically, you’re going to be interested in the correlation of the read coverages for different replicates and different samples. What you want to see is that replicates should correlate better than non-replicates. The ENCODE consortium recommends that for messenger RNA, (…) biological replicates [should] display 0.9 correlation for transcripts/features. For more information about correlation calculations, see the background description for plotCorrelation.
tools: multiBamSummary followed by plotCorrelation
- input: BAM files
you can compare as many samples as you want, though the more you use the longer the computation will take
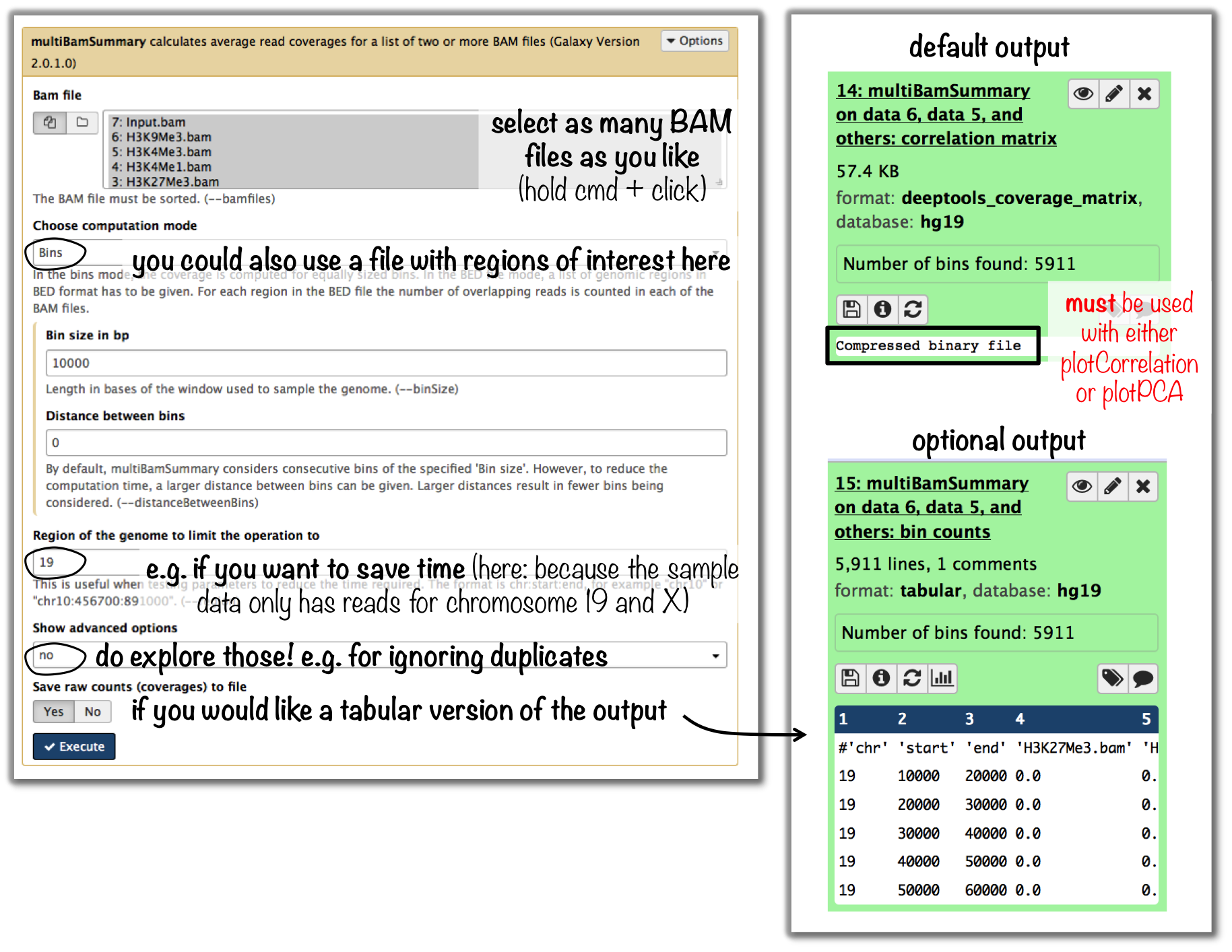
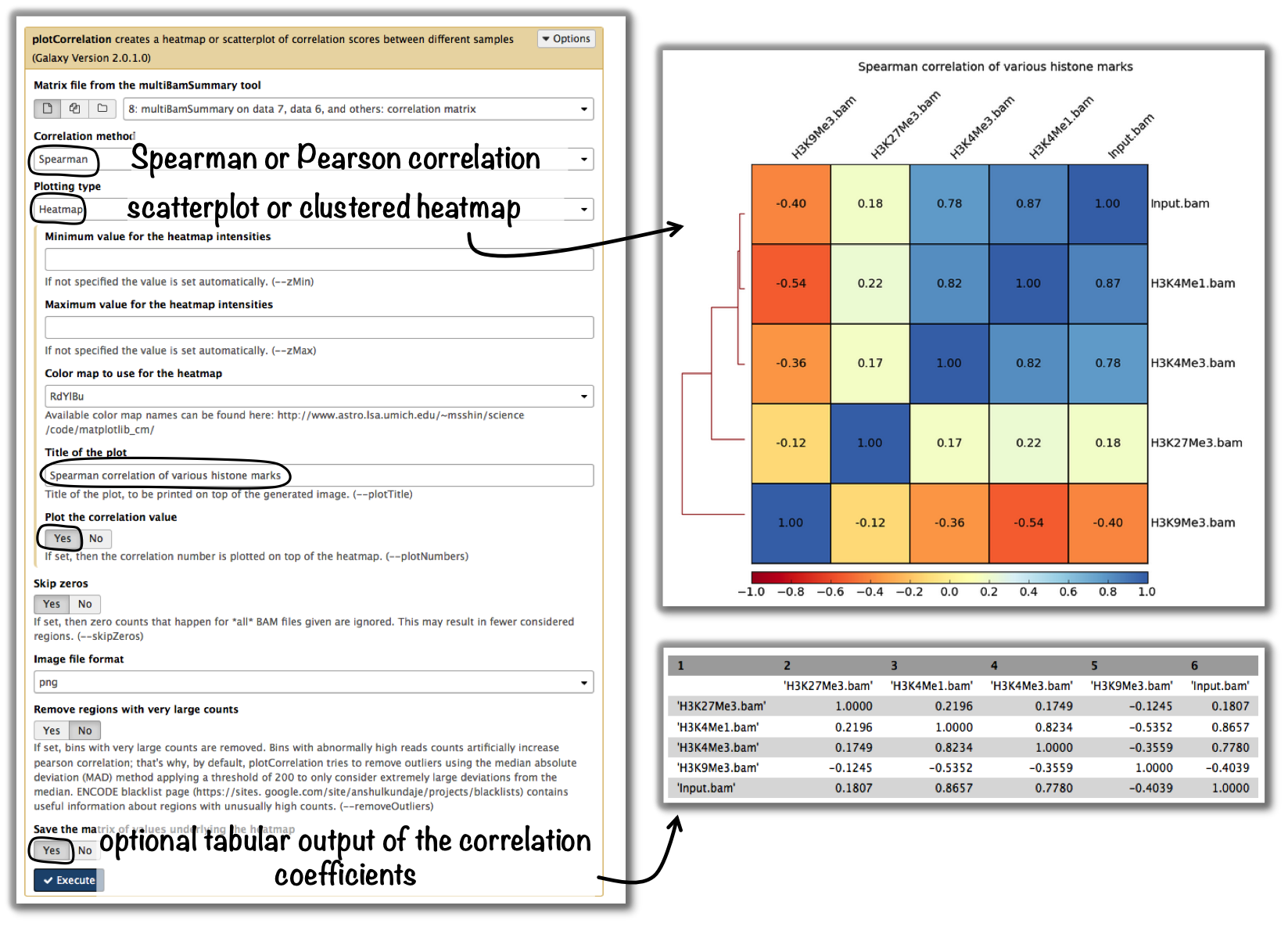
Tip
If you would like to do a similar analysis based on bigWig files, use the tool multiBigwigSummary instead.
How do I know whether my sample is GC biased? And if it is, how do I correct for it?
input: BAM file
use the tool computeGCBias on that BAM file (default settings, just make sure your reference genome and genome size are matching)
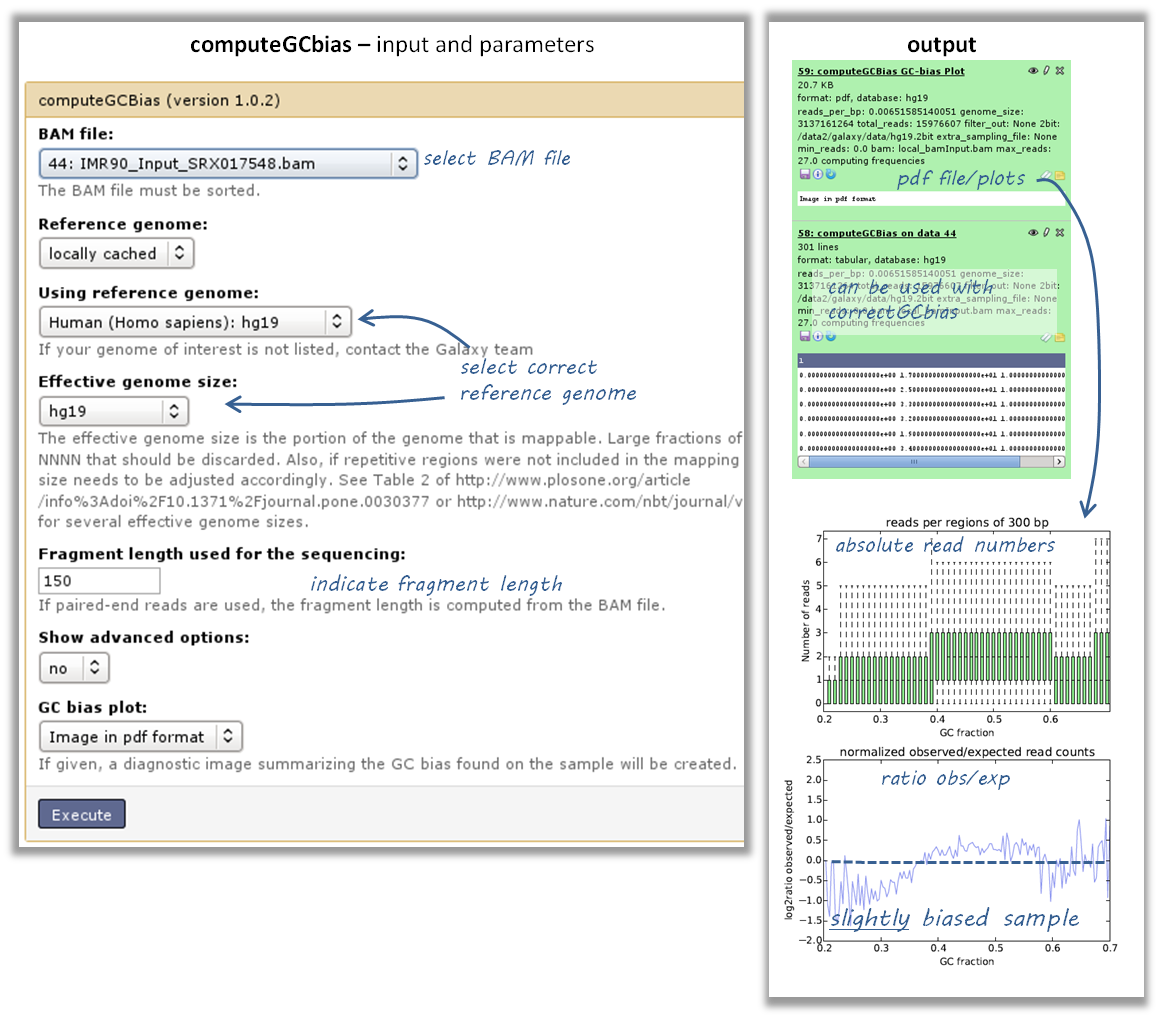
have a look at the image that is produced and compare it to the examples here
if your sample shows an almost linear increase in exp/obs coverage (on the log scale of the lower plot), then you should consider correcting the GC bias - if you think that the biological interpretation of this data would otherwise be compromised (e.g. by comparing it to another sample that does not have an inherent GC bias)
the GC bias can be corrected with the tool correctGCBias using the second output of the computeGCbias tool that you had to run anyway
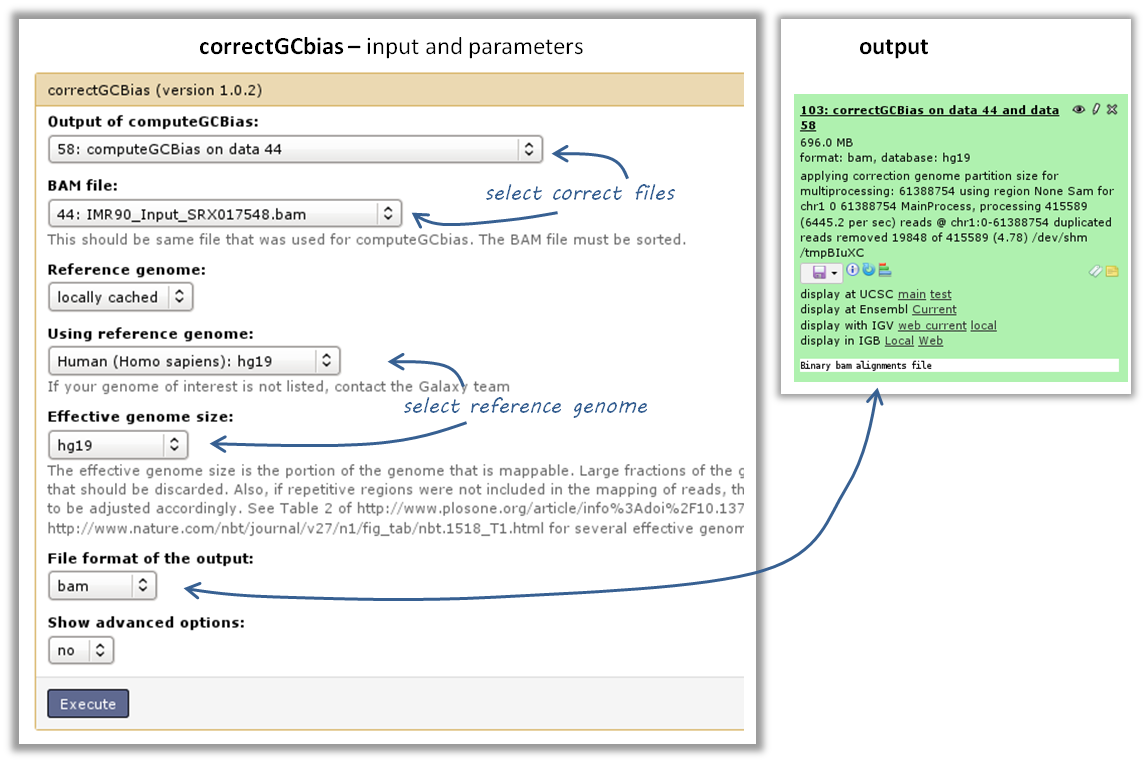
Warning
correctGCbias will add reads to otherwise depleted regions (typically GC-poor regions), that means that you should not remove duplicates in any downstream analyses based on the GC-corrected BAM file. We therefore recommend removing duplicates before doing the correction so that only those duplicate reads are kept that were produced by the GC correction procedure.
How do I get an input-normalized ChIP-seq coverage file?
input: you need two BAM files, one for the input and one for the ChIP-seq experiment
tool: bamCompare with ChIP = treatment, input = control sample

How can I compare the ChIP strength for different ChIP experiments?
tool: plotFingerprint
input: as many BAM files of ChIP-seq samples as you’d like to compare (it is helpful to include the input control to see what a hopefully non-enriched sample looks like)
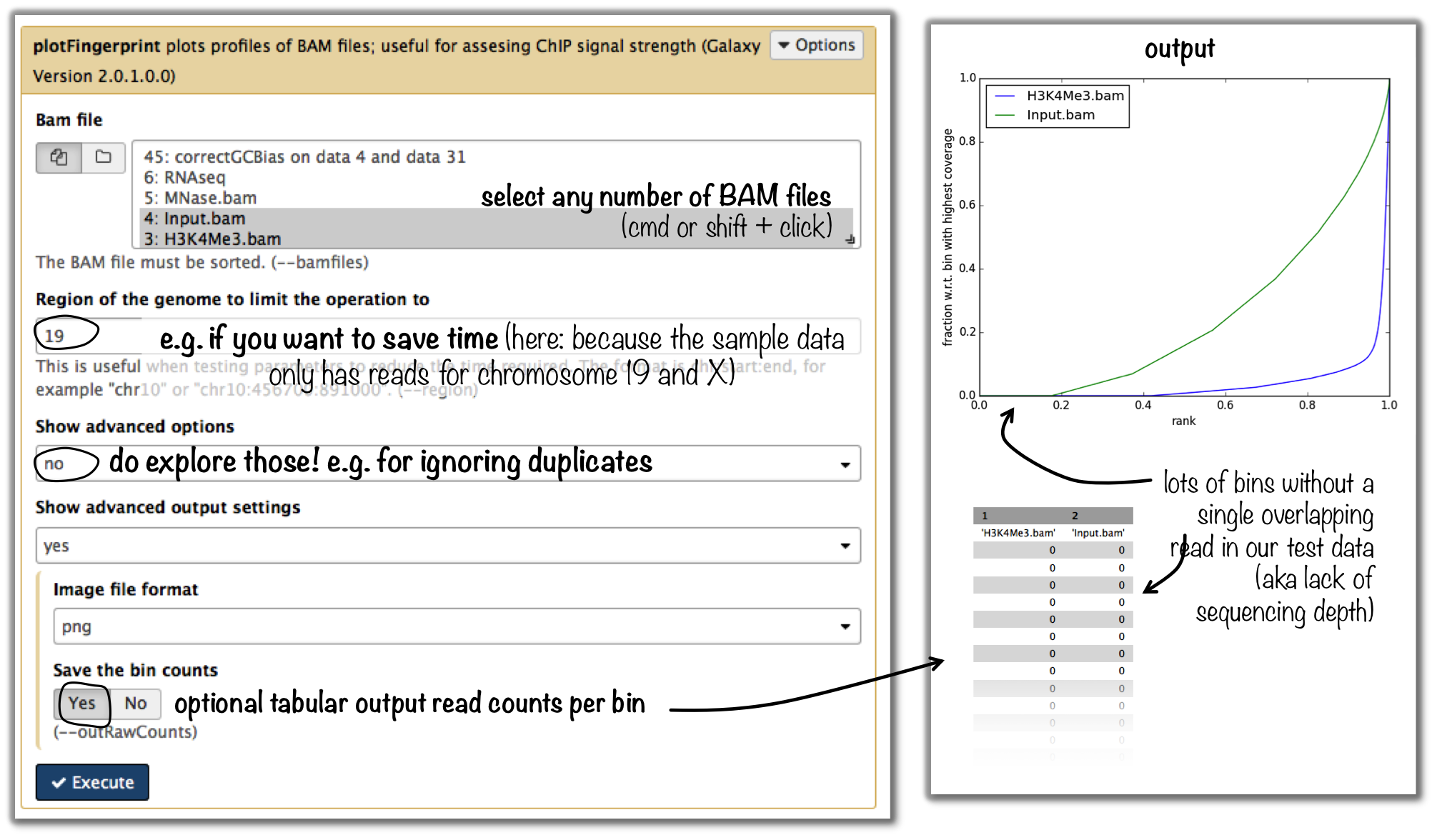
Tip
For more details on the interpretation of the plot, see plotFingerprint or select the tool within the deepTools Galaxy and scroll down for more information.
Heatmaps and summary plots
How do I get a (clustered) heatmap of sequencing-depth-normalized read coverages around the transcription start site of all genes?
tools: computeMatrix, then plotHeatmap
- inputs:
1 bigWig file of normalized read coverages (e.g. the output of bamCoverage or bamCompare)
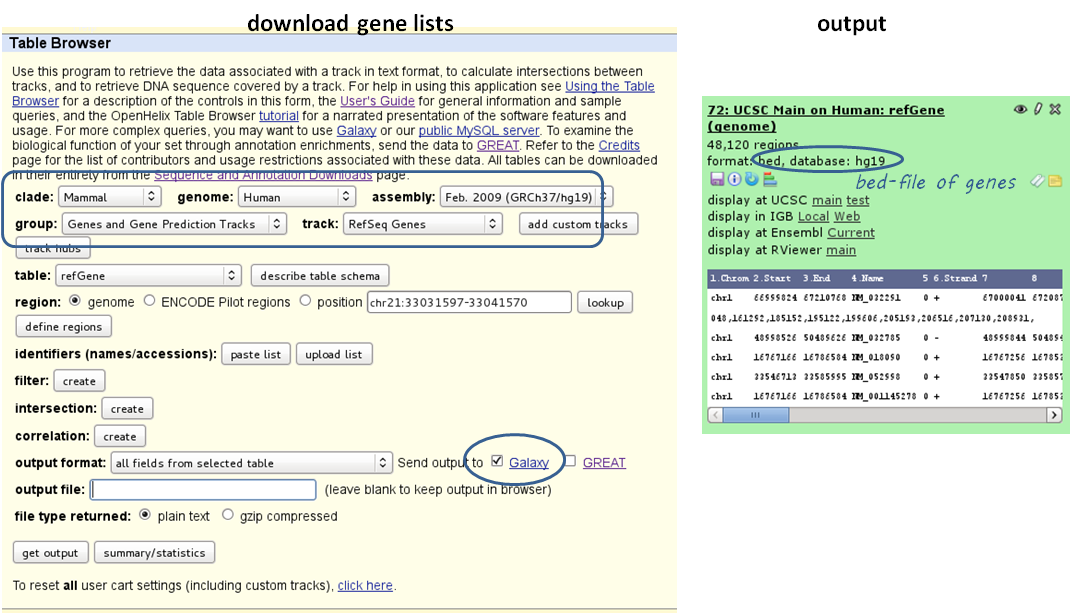
1 BED or INTERVAL file of genes, e.g. obtained through Galaxy via “Get Data” –> “UCSC main table browser” –> group: “Genes and Gene Predictions” –> (e.g.) “RefSeqGenes” –> send to Galaxy (see screenshots below)
use computeMatrix with the bigWig file and the BED file
indicate
reference-point(and whatever other option you would like to tune, see screenshot below)
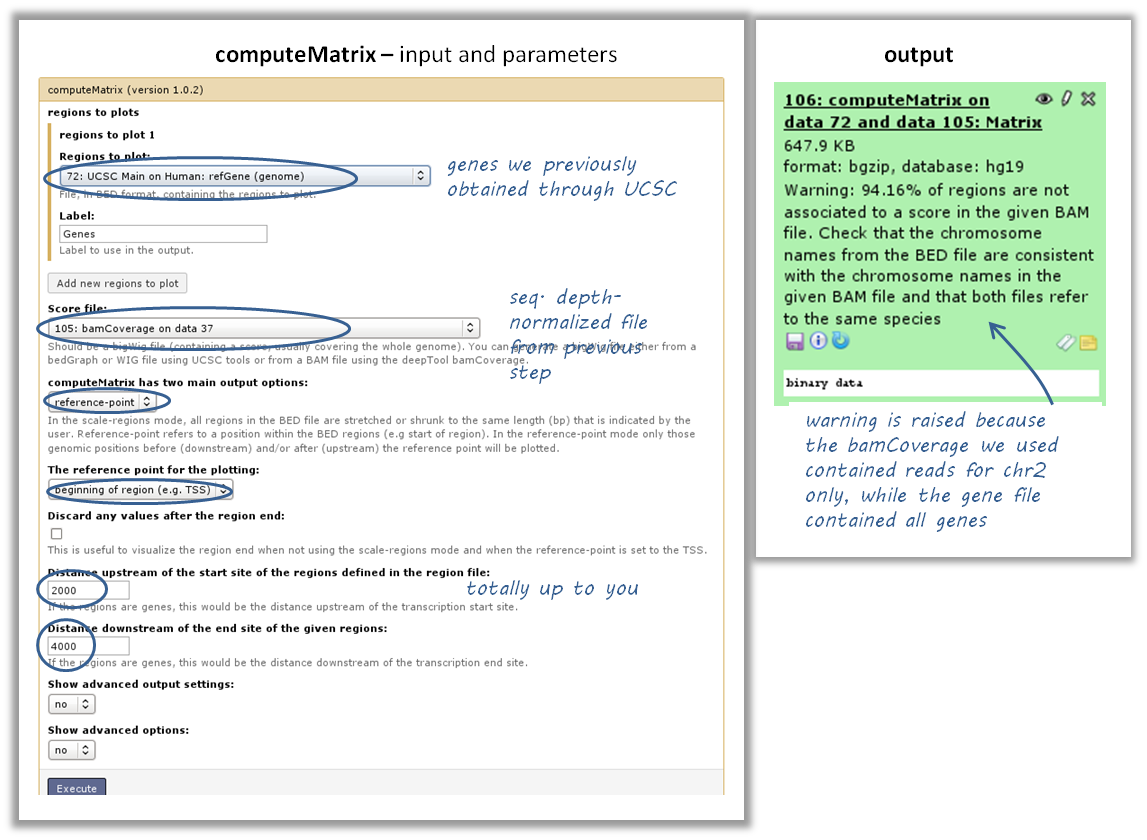
- use the output from computeMatrix with plotHeatmap
if you would like to cluster the signals, choose
k-means clustering(last option of “advanced options”) with a reasonable number of clusters (usually between 2 to 7)

How can I compare the average signal for X-specific and autosomal genes for 2 or more different sequencing experiments?
Make sure you’re familiar with computeMatrix and plotProfile before using this protocol.
- tools:
Filter data on any column using simple expressions
computeMatrix
plotProfile
(plotting the summary plots for multiple samples)
- inputs:
several bigWig files (one for each sequencing experiment you would like to compare)
two BED files, one with X-chromosomal and one with autosomal genes
How to obtain a BED file for X chromosomal and autosomal genes each
download a full list of genes via “Get Data” –> “UCSC main table browser” –> group:”Genes and Gene Predictions” –> tracks: (e.g.) “RefSeqGenes” –> send to Galaxy
filter the list twice using the tool “Filter data on any column using simple expressions”
first use the expression: c1==”chrX” to filter the list of all genes –> this will generate a list of X-linked genes
then re-run the filtering, now with c1!=”chrX”, which will generate a list of genes that do not belong to chromosome X (!= indicates “not matching”)
Compute the average values for X and autosomal genes
use computeMatrix for all of the signal files (bigWig format) at once
supply both filtered BED files (click on “Add new regions to plot” once) and label them
indicate the corresponding signal files
now use plotProfile on the resulting file
important: display the “advanced output options” and select “save the data underlying the average profile” –> this will generate a table in addition to the summary plot images
